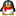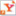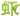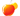3. 界面区域介绍
区域1是一个文本输入区,默认文字有三行,都是以http开头,大家一看就知道在这里输入要spider的站点的网站地址(建议每次只spider一个网站)。
区域2是spider选项,搜索深度是指对这个网站spider到几级目录,每页链接数是指针对某个网页最多抓取多少个下面的链接网页。默认情况下都为0,指的是对这个站点进行全站spider。
区域3显示数据库状态信息,包括已经spider的网站、关键词、索引以及正在spider的站点信息等。
区域4是一个下拉列表框,罗列出已经spider的站点的网址,选中其中的一个站点,在区域5可以对其进行清除和更新操作。
区域5不仅提供了对区域4中所选站点的清除和更新操作外,还提供了相关的统计信息入口和对spider的控制等。
4. 针对特定站点运行spider
如果你对天极软件频道的内容很感兴趣,你就可以做一个比google更专业的搜索引擎来搜索天极软件的内容,你的这个搜索引擎将比google更全面更深层次。下面我们以spider天极软件频道的内容为例介绍一下如何spider一个网站。
1)在图2的区域1中输入http://soft.yesky.com,搜索深度和每页链接数都保持默认为0
2)单击spider按钮,页面跳转到spider信息页面,程序开始自动spider站点http://soft.yesky.com的内容。
注意:spider网站的过程非常缓慢,如果该网站内容太多,这个过程可能会延续几小时到一天,但你不必担心脚本运行超时,因为系统的timeout时间被设置为最长达48小时。在这个过程中,你也可以中断spider程序的运行,并能重新启动spider程序运行未spider完的网站。需要注意的是若在这个过程中你不小心关闭了spider运行页面,但事实上系统并没有停止spider,仍在消耗系统资源。你可以重新打开spider页面,点击停止spider链接方可释放系统资源。

(图3)
5. 利用PHPdig进行搜索
经过一段时间后,spider程序运行的结果是将http://soft.yesky.com网站上的信息抓取到服务器数据库中,主要是对方内容的title信息、关键词信息和页面地址信息等,此时,你就可以通过访问search.php进行搜索了。

(图4)
你可以选择搜索结果显示的条数,可以选择模糊查找还是精确查找,另外你可以选择针对某个站点的搜索,默认情况下搜索已经被spider的所有站点。

(图5)
上图是搜索“QQ2006”的搜索结果页面。
6. 存在的问题
由于PHPdig的语言设置问题、系统的分词问题以及MYSQL数据库的字符处理问题等,PHPdig对汉语词汇的搜索还存在许多不确定因素,这些东西都有待我们进一步去解决和完善。